As ChatGPT becomes a household topic and AI integrates into nearly every industry, organizations are looking to maximize the benefits of one of the greatest technological innovations of the millennium. They aim to avoid missing out on any benefits while mitigating risks and managing obstacles. Data is critical for AI models and applications but real-world data may not always be accessible, feasible, or prudent depending on the use case.
Synthetic data has emerged as an attractive alternative, but in which applications does it make the most sense and what considerations should organizations look into before diving in?
Synthetic Data in the World of AI
Synthetic data refers to artificial data that is generated by using relational databases and generative machine learning models to generate an alternate or expanded set of data. Its purpose is to mimic real-world data to be used in Artificial Intelligence (AI) applications in order to test or demonstrate the algorithms. It’s often leveraged to avoid compromising personal, private data while still allowing for analysis and model training.
The techniques used to generate synthetic data are challenging to reverse engineer. Each technique should be mindful of the ultimate desired business objective. Some usage is tactical while other is strategic. This makes synthetic data attractive to companies who want to reduce data costs for simple infrastructural tests or want to share their latest insights and developments without potentially exposing proprietary information or personal data.
As privacy concerns around the data AI is trained on continue, we can expect to see the use of synthetic data grow, especially in fields such as healthcare and industries like finance.
Use Cases and Scenarios Where Synthetic Data Makes Sense
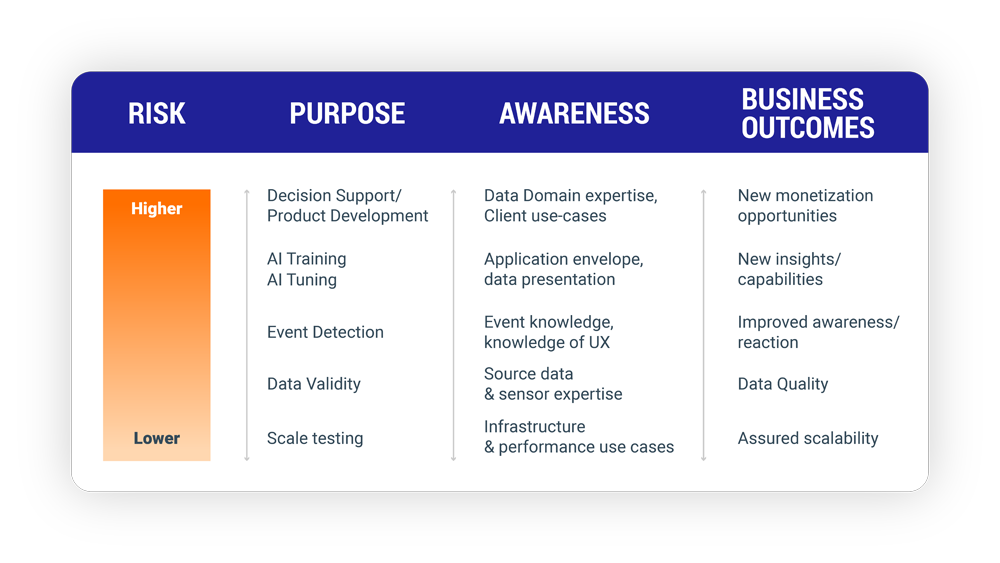
When might you want to experiment with synthetic data? Let’s say you want to performance test a large AI instance at full load. In this scenario, it would be wise to create synthetic data to support those tests at scale. The valid synthetic data supports testing without exposing real-world data to potential risks or incurring the costs of accessing other data assets.
Likewise, a company could use synthetic data when validating a threat assessment monitor, watching real-world data for event detection. The synthetic data could provide the stimulus of a class of events that are part of the detection capabilities without waiting for an event to happen in the real world. Subject matter experts with knowledge of these types of threats, under the supervision of a data analyst, can help to validate the detection of a broad spectrum of specific violations.
Ultimately, these tests are only as effective as the AI or human capacity to anticipate potential threats. Another use case would be the testing of data filters on data ingestion pipelines. Synthetic data could be leveraged to test the performance and effectiveness of validation filters, how quickly algorithms tune to, or track new phenomena.
Synthetic data is also suitable for tuning and training AI models. The use case of tuning sensitivity is predicated on having experts in the Large Language Model domain or other underlying technology. Ultimately, you want to ensure the algorithm is listening to the new data. Alternately, in the case of training AI models, it is more than just listening; you are teaching them to react in the right way. This requires access to people who are knowledgeable of the data and how a human with the related domain expertise would respond so the model can be trained to mimic that response.
You want deep domain knowledge to be possessed by both human and AI assets. It allows for a precise definition of what the AI are supposed to- and not supposed to- be trusted with and the limits of their decision-making powers. Stakeholders should also implement methods for monitoring data skew in their synthetic data augmentation plan. As important as the machine algorithms are – it is equally critical to provide regular training to the people who consume the outputs of the AI – so they are always giving the business the best of these decision support systems.
Synthetic data can also be leveraged in scenarios where an organization wants to augment its data sets in size or diversity. Instead of procuring additional real-world data, synthetic data can provide greater volume and diversity for models to be trained upon. Likewise, organizations may want to generate synthetic data to research potential scenarios that are too costly or unfeasible to replicate with real, raw datasets.
Risks and Considerations
There are some other considerations to keep in mind when working with synthetic data. You can think of this type of data as similar to synthetic drugs in the pharmaceutical industry. In order to determine the safety and efficacy of these synthetic drugs, large, focused tests were performed first. The use of synthetic data requires the same kind of rigor. It won’t be effective if it isn’t reflective of the data it’s trying to mimic.
It’s also important to consider the impact of synthetic data on your delivery horizon as it can both lengthen and shorten it. Having a clear understanding of what kind of outcomes the synthetic data supports (e.g., scale testing, filtering/validation, learning speed, model training) is the ideal starting place. Synthetic data coupled with human innovation can also identify new rhythms in the chaos or monetization opportunities for specific clusters of data for certain classes of clients. Having watchful new product developers involved with these innovation efforts is critical to find more ways to differentiate data refineries.
Ultimately, synthetic data isn’t an end-all, be-all solution for mitigating AI privacy concerns and expanding access to data. When making the decision to leverage synthetic or real-world data, be sure to factor in the potential impact of generalization. In some cases, particularly where accuracy and variability matter most, real world data may be a better choice. Synthetic data can’t always accurately reflect the complexity and diversity found in real-world data sets. Furthermore, if you’re working in an industry where regulations come into play, research all legal implications related to synthetic data before using it.
A Strategic Way Forward with Synthetic Data
You can tap into the power of AI while avoiding privacy risks through the strategic use of synthetic data with the help of 3Pillar. Our expertise lies in providing innovative digital solutions to the modern problems businesses are facing today.
In the world of AI, we’ve worked with synthetic data to support healthcare providers in delivering high-quality treatment solutions. Our team created edge-case examples for medical imagery to check signal-to-noise specifications and set parameters for regulatory testing of the image analysis algorithms. These controlled efforts allowed the provider to simultaneously improve real-world patient outcomes via smarter treatment selection as well as expanding the boundaries of the predictive capabilities for their medical practitioners.
Our team can help you assess whether synthetic data meets your organization’s needs and if so, provide a path forward to achieving your goals while meeting requirements and mitigating risks. Contact 3Pillar today to get started.